python信息收集edusrc学校根域名
前言:总体思路大体上分两步
- 采集edu全国高校漏洞排行榜所有学校名,存入文档
- 通过bing搜索所有学校名,取第一页结果通过正则去匹配指定后缀根域名,存入文档
一.采集edu学校名
效果图如下:
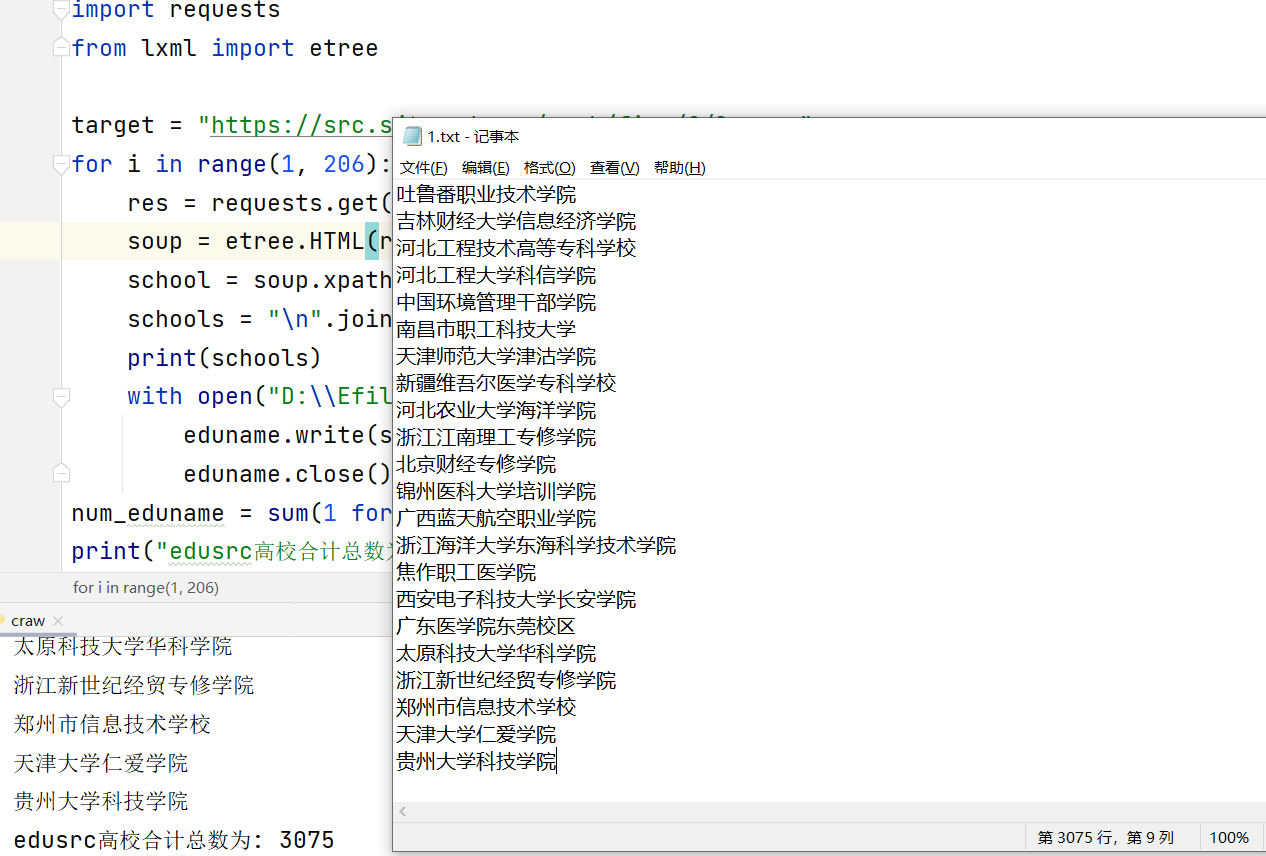
代码如下:
import requests
from lxml import etree
target = "https://src.sjtu.edu.cn/rank/firm/0/?page="
for i in range(1, 206):
res = requests.get(url=target + str(i)).content.decode("utf-8")
soup = etree.HTML(res)
school = soup.xpath("//td[2]/a/text()")
schools = "\n".join(school)
print(schools)
with open("D:\\Efile\\python_pycharm\\1.txt", 'a') as eduname:
eduname.write(schools + "\n")
eduname.close()
num_eduname = sum(1 for line in open("D:\\Efile\\python_pycharm\\1.txt", "r"))
print("edusrc高校合计总数为:", num_eduname)
二.批量采集根域名
效果图如下:
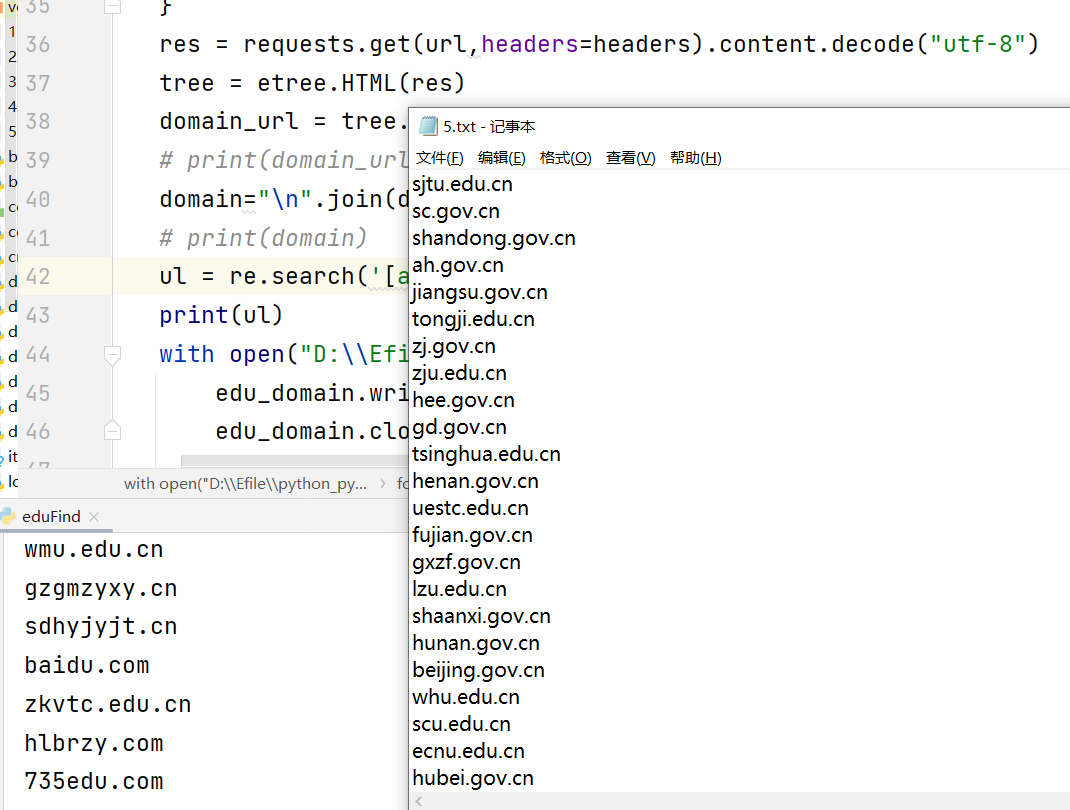
代码如下:
import requests, re
from lxml import etree
with open("D:\\Efile\\python_pycharm\\2.txt", 'r', encoding='utf-8') as f:
for line in f:
contents = line.strip()
# print(contents)
url = "https://cn.bing.com/search?q=" + contents
# print(url)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
}
res = requests.get(url, headers=headers).content.decode("utf-8")
tree = etree.HTML(res)
domain_url = tree.xpath('//div/cite/text()')
# print(domain_url)
domain = "\n".join(domain_url)
# print(domain)
ul = re.search(
'[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(.(edu.cn|edu-dc.cn|org.cn|ac.cn|net.cn|com.cn|gov.cn|edu.hk|org|com|cn|net))\.?',
domain).group()
print(ul)
with open("D:\\Efile\\python_pycharm\\5.txt", 'a') as edu_domain:
edu_domain.write(ul + "\n")
edu_domain.close()
思考:1.因搜索引擎第一条结果不一定是学校,导致正则匹配根域名不完全准确,最终结果需替换百度百科 搜狗 知乎域名为空。2.数据量太多,采集未加入多线程,速度相对较慢,各位客官可自行修改完善。
附录:
